Hi! Are you feeling overwhelmed by the manual process of sifting through countless PDF resumes? Have you ever wished for a way to intelligently extract resume content, or even automatically analyze how well a candidate fits a job description?
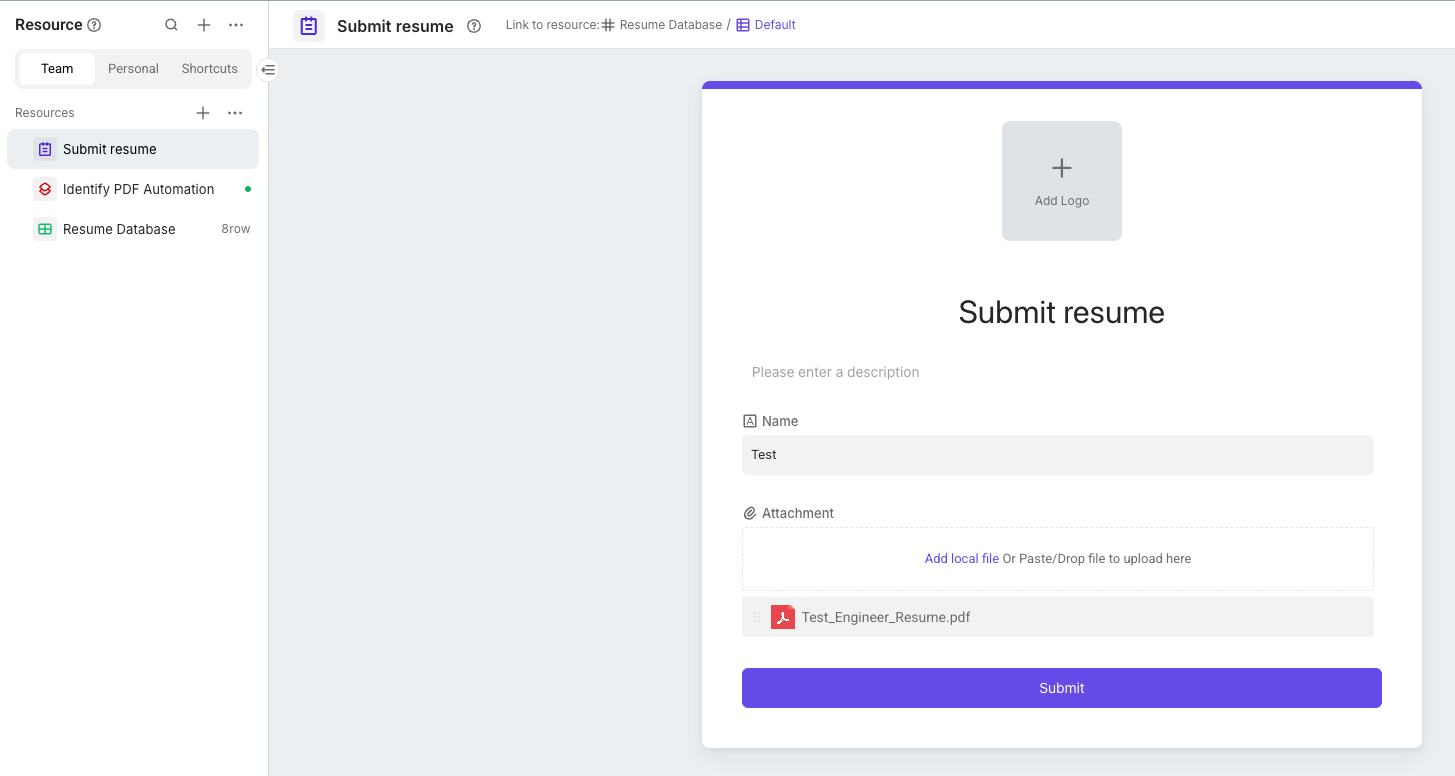
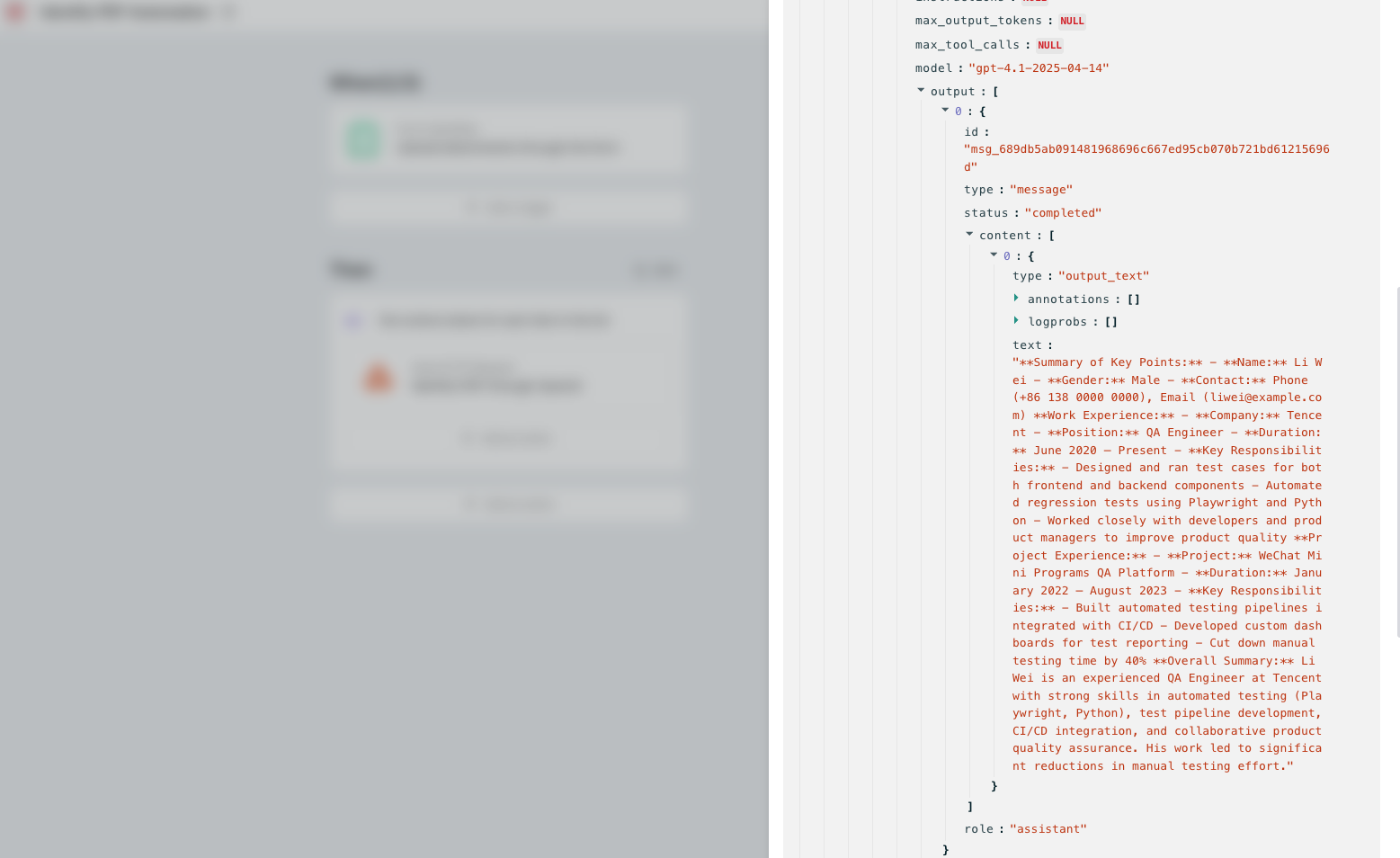
Today, we’ll walk you through a practical example of how to use the OpenAI API to automate the processing of PDF files. In this tutorial, we’ll build an automation flow that gets triggered when you upload a PDF resume via a form, and then uses OpenAI to recognize and analyze its content.
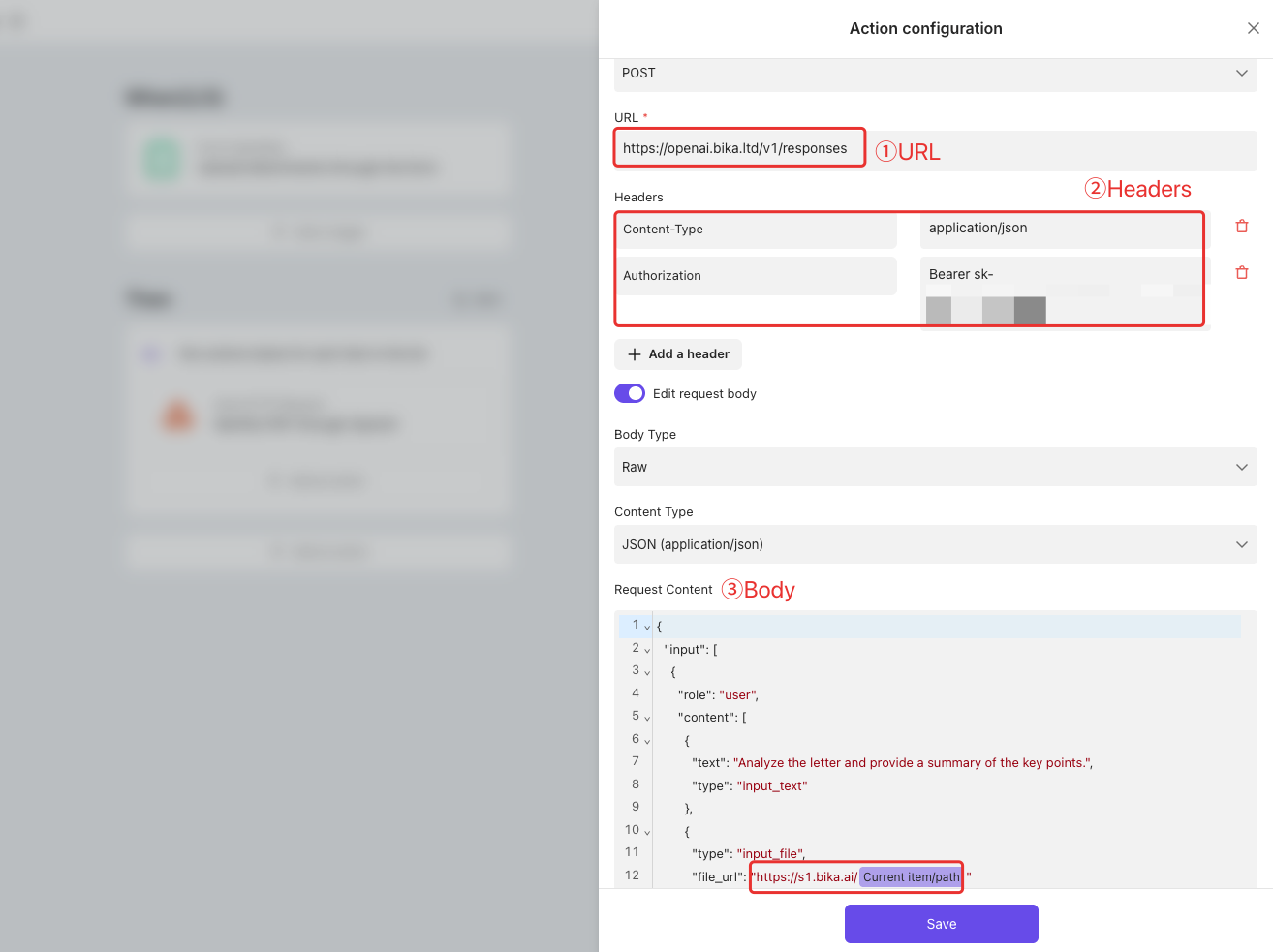
After you upload your resume PDF through the form feature, the PDF file will be stored on Bika’s cloud. When we call OpenAI’s API, we need to include the publicly accessible URL of the PDF file in the post data when making the request. This allows the LLM to properly perform text extraction and analysis tasks on your PDF resume.
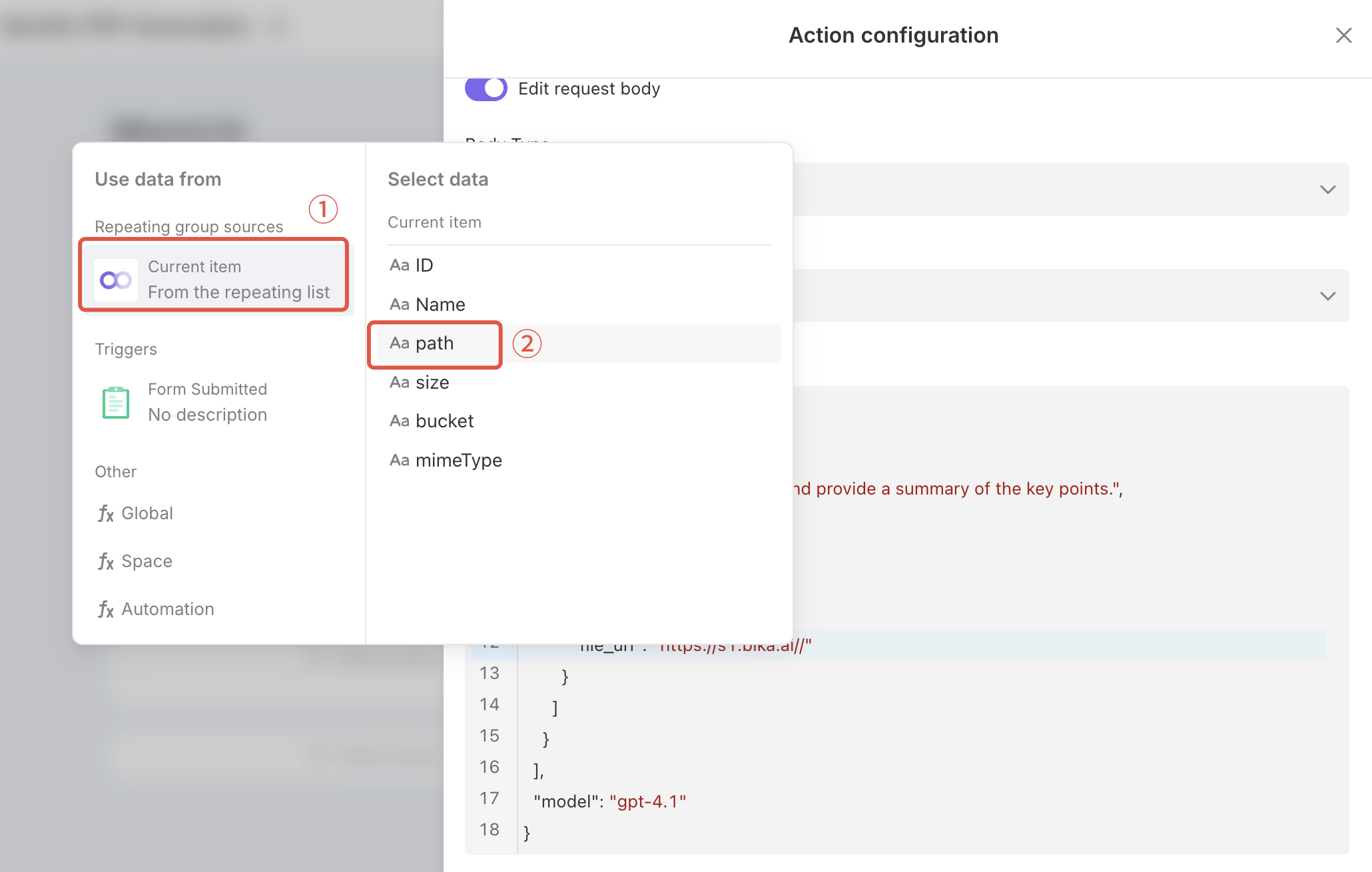
First, we need to find the storage path of your PDF attachment.
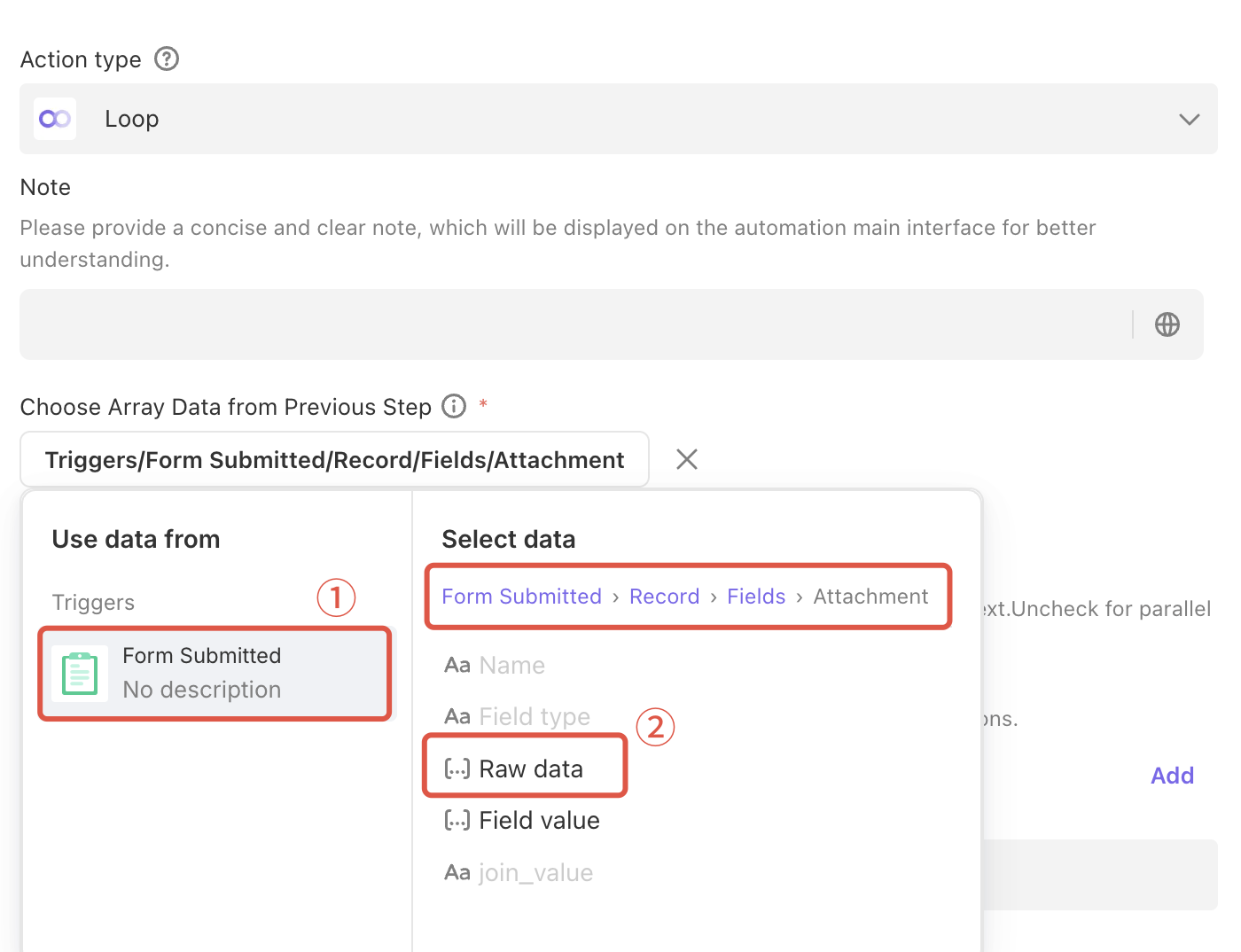
In your automation flow, find the Loop action (In the database, the value of an attachment field is an array, which means multiple attachments can be stored in a single cell. Therefore, a loop action is required to iterate through and process them.).
Select “From Submitted > Record > Fields > Attachment > Raw Data”